About Mojeek; Search Engines and Our Technology Stack


We frequently get questions, through social networks or our support inbox, about Mojeek's tech stack and the work that goes into providing the world with a true alternative in search. To spread the answers to some of these questions further than the walled garden of our email inbox, or the social graphs of Twitter, Mastodon, and Reddit, we thought it would be a good idea to publish some of them on our blog (here are part 1, part 2 and part 4 of these FAQs).
Search Engines
What type of search engine is Mojeek?
Mojeek is a crawler-based search engine built from the ground up, this means it has its own index of web pages. Mojeek doesn’t rely on any other search engines to make up its index, it is completely independent. For more details check out this article about what a crawler-based search engine is.
What crawler-based search engines are there?
Google, Bing, Mojeek, Yandex, and Gigablast are the only crawler-based search engines that are targeted at a Western consumer audience and are active. We maintain a resource on Search Engine Map which shows the links between different crawler-based and metasearch engines and Twitter lists of various search engine types.
Which crawler-based search engines don’t track you?
Only Mojeek, as far as we are aware.
What is the difference between Mojeek and other privacy search engines?
Mojeek is the only privacy search engine that has its own index of pages. Other privacy search engines are actually metasearch engines which pay or partner with a crawler-based search engine to gain access to their index; as shown here. You will note that many of them use Bing. For more information, check out this article all about how Mojeek is different.
Where can I submit my site to Mojeek?
We don’t provide an ‘add URL’ service as we have received lots of spammy submissions through it in the past, so we prefer to find sites naturally. We recommend getting prominent and genuine links to your site; this will help Mojeek and other search engines find and rank your website.
Mojeek Technology Stack
How does Mojeek get its results?
As a crawler-based search engine, Mojeek has a program known as ‘spider’ or ‘bot’ which goes out and gets web pages. Using links to get from webpage to webpage, it then indexes these pages just like an index in the back of a book. It then ranks the web pages it gets by relevance and quality metrics. What determines the relevance and quality of web pages is based on both the contents of the page and its incoming links, judging this using the quality of the source page and the associated link text.
How does the Mojeek bot crawl the web?
We provide details on our bot page.
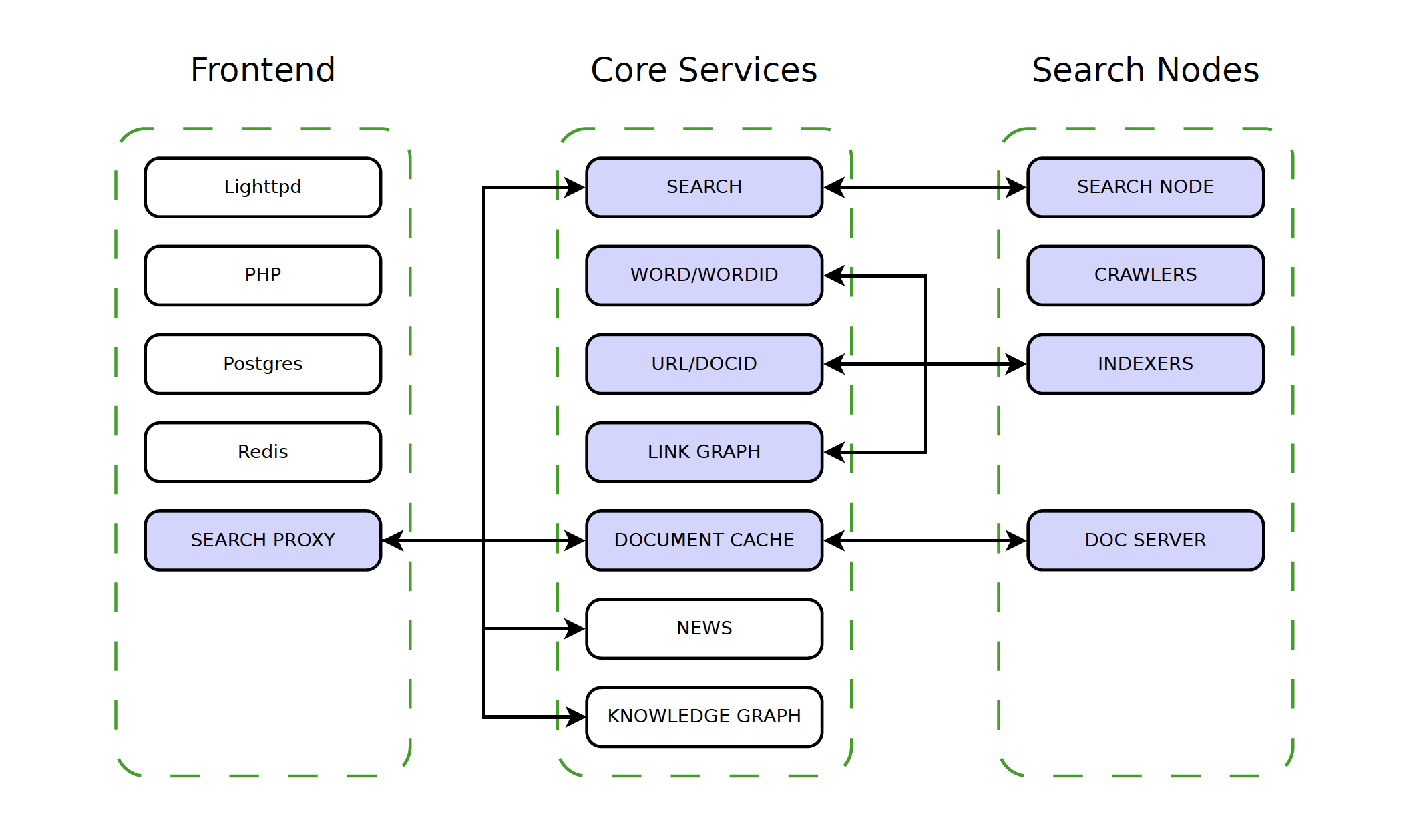
What is your technology stack?
Our technology stack is built from the ground up and designed in order to deliver the best results that it possibly can, as fast as possible. In the backend we have crawlers which go out and fetch webpages for the indexers; these indexers extract the page content and links, storing it using WordIDs and DocIDs. This is then combined with data from our link graph in order to create searchable indexes containing these records. When you make a query on Mojeek’s frontend, which brings together lighttpd, PHP, Postgres, and Redis, your query is sent to an available search server, which in turn sends your query to all available search nodes (or shards - fragments is what we call them) in the backend, at the same time calls are made to our knowledge graph and news services. The search nodes return the most relevant results from their index to the search server, the search server combines these results and when it has decided which results are to be displayed, requests those documents' text from the document server. If a document’s text is not already in the document server’s cache, it will request it from the correct search node. The search server will now generate the snippets for each result to be displayed using the document’s text and your search query. Mojeek uses a wide variety of ranking factors when deciding which results to display, such as: the number of times a page has been linked to, and the number of times a term appears on a page. The resulting pages from our index will appear on the search page that you are directed to in order of relevance as determined by these factors. This is of course an oversimplification of the ranking factors, but these are the basic concepts.
Why do you build your own servers?
Building our own servers means that we have complete control over the technology that powers Mojeek; this means that we are putting together machines suited to our specific use case and selected based upon what we know about the equipment providers.

Why do you use Custodian rather than a major cloud service?
The green credentials of the Custodian Data Centre are very important to us; also the location in Kent is very practical for some people working at Mojeek. Having ownership of our own servers is important to us in the same way that self-hosting our documents, internal chats, and video calls is; this ownership means that we don’t have to rely on and trust third parties to supply us with our infrastructure. Major cloud service providers such as Microsoft, Amazon, and Google engage in practices that just do not fit with our mission and values. On top of this, not using those services saves us very large amounts of money in running costs.
What is the size of your index?
At the time of writing the Mojeek index comprises over 3.6 billon webpages; this is equivalent to about five hundred Wikipedias. We aim to double the number of pages over the next 12 months.