Search Technology Values 18 May 2026The Switch to Alternative Search EnginesThe trend towards alternative techmojeek3 min
Search Technology Values29 January 2026A Brief History of SearchingHow searching for information has evolved over time.colin8 min
Company Search Values09 September 2025Mojeek is Not an Answer EngineMojeek is about Search. AI is not the Answer.colin3 min
Policy Search Values09 April 2025SearchceptionThe illusion created by the merging of browsers with search engines.colin3 min
Privacy Technology Values25 March 2025Learning and Sharing about Alternatives to Big TechWhat you can do once you've decided to avoid Big Tech?colin3 min
Privacy Technology Values19 February 2025Leaving Big TechA range of tools available to help you kick Big Tech companies out of your life...josh6 min
Search Technology29 January 2025Topical Custom Search EnginesHow the Mojeek API can be used to build topical search engines...colin3 min
Community Search08 January 2025Getting the Best out of Keyword Web SearchA guide on how to use Mojeek effectively...colin6 min
Search Technology11 December 2024How To Use Focus From Your URL BarTrigger Focus engines from the URL bar – even those which aren’t in the...josh5 min
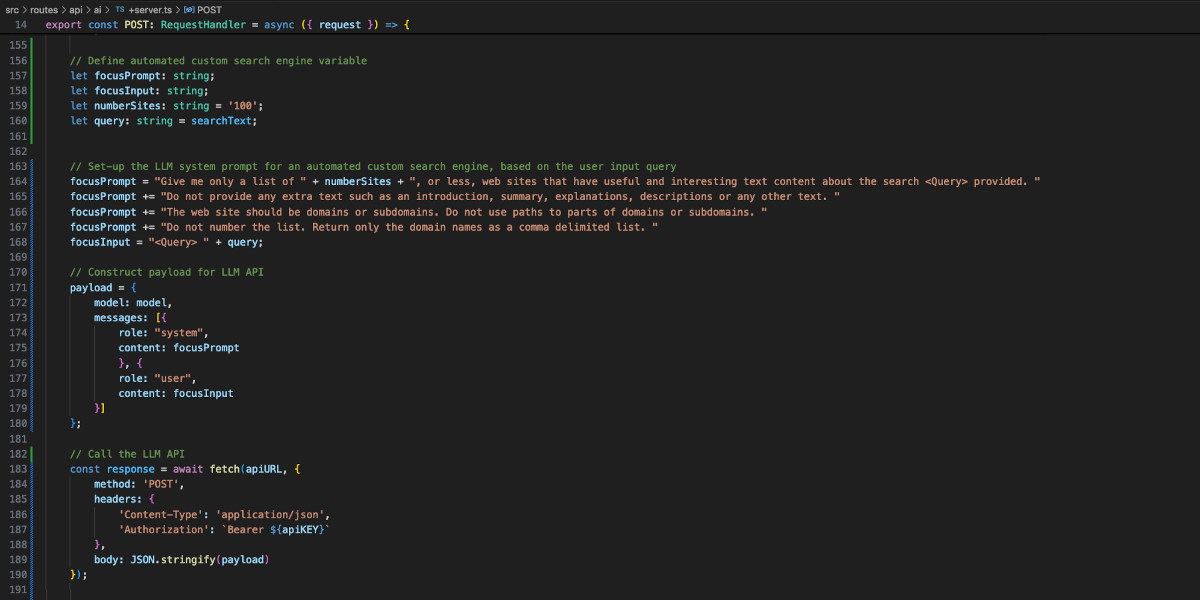
Search Technology05 December 2024Automating Custom Search EnginesImagine automating the process of searching across particularly-relevant sites.colin5 min
Search Technology Values 30 May 2023Generative AI Threatens Diversity and HyperlinksThere is no doubt that generative AI and chatbots can be...colin6 min
Search Technology 13 December 2022How To Search (On Mojeek)This article outlines some of the ways in which Mojeek is different from other...josh4 min