No-Tracking Search, How Does it Work?

![]()
Mojeek is one of seven international real Web search engines and the only one outside of USA, Russia, and China. As the only one of two that do not track, Mojeek offers unique and important benefits to its global users. Search with surveillance was born in Silicon Valley and has been adopted in Russia and China. Search without surveillance was born in the UK, at Mojeek, in 2006. Here is the Mojeek perspective on search engines really work and what goes into building a real search engine.
The information in this article is now also available in video form on YouTube and PeerTube.

Search engines are our main navigators to useful information on the Web. We use them to conveniently hop to a known destination. We use them to discover and learn. We check our assumptions and pose queries. And yet, very few people understand the work that goes into building a large-scale general search engine. One of those few people is Mojeek founder, Marc Smith, who has built from scratch a full search technology stack, since starting it as a hobby project in 2004.
Numerous search engines have come and gone since 2004. Today, the only general and international web search engines are Baidu, Bing, Gigablast, Google, Mojeek, Sogou and Yandex. Yes, only seven. Seven of what we call real search engines. Later in this article we review the main components that make up a real search engine. This will help your understanding of what goes on when you use Google or something else. But first, some important context.
Search Realities
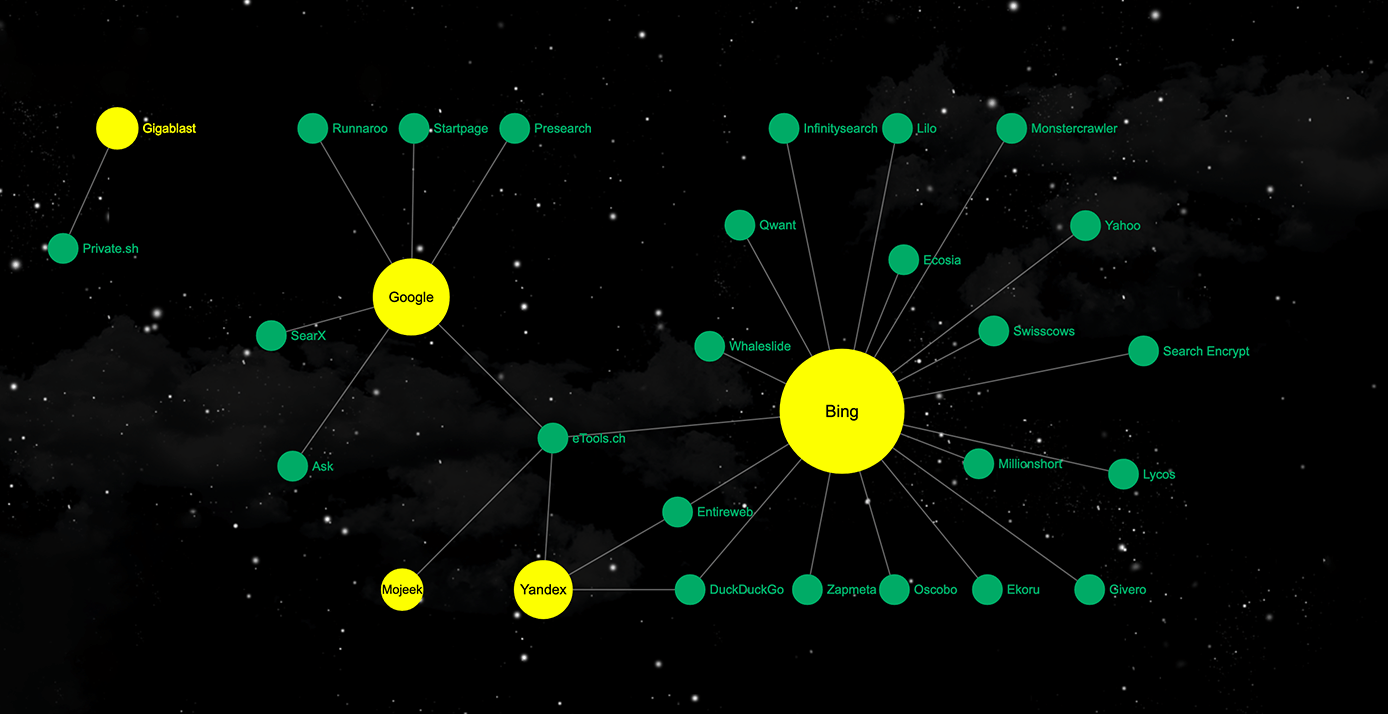
The biggest challenge for a large-scale search engine is building a large, and efficiently readable, index of the Web; one that covers billions of pages. Because of this challenge a lot more companies (at least 40) opt to provide search or metasearch services. These services, examples being DuckDuckGo, Ecosia, and Qwant, get their search results and ads from Bing (Microsoft). A few others, such as Startpage, get the same from Google.
Without an index of their own, search service companies like these are dependent on real search engines. To understand the way in which different search services guide your journeys across the Web, you really should understand the index they are using. And importantly the companies they support, depend upon, and are constrained by. At Mojeek, we created searchenginemap.com so you can see these dependencies.
At Mojeek our own technology stack means we have no such dependencies. We only use the services of an independent data centre. As we scale up, we are keen to minimise our carbon footprint so we use the Custodian data centre in Kent - the UK’s greenest provider.
So what makes up a real search engine? In practice there are three main parts as explained in the following sections; a crawler, an index, and ranking methodologies.
Crawling
Crawling is the process by which Internet bots (known in search as a spiders) systematically browse the Web and discover the content needed to build a searchable index. As spiders crawl webpages, they build up lists of URLs (Uniform Resource Locators) found on visited pages. These lists of URLs serve in turn to direct the spiders to further indexable pages.
On each page, spiders take only relevant pieces of data, such as the page content and links, putting the resulting bundle into a queue for detailed indexing. Even though crawling is a far from a simple task, indexing requires around 100 times the computing resources of crawling.
Indexing
Indexing takes data gathered by the crawler and puts it into compact data structures. These processes involve things such as parsing, sorting, and compressing the contents of each page. Once a page is in the search index, it becomes a candidate to be displayed in response to relevant search queries. The indexing process and structure has to be designed well so that a search engine can efficiently serve results. Whilst a search index of one million pages is relatively straightforward, and will suffice for most internal site search functions, an index of billions of webpages is a completely different scale of challenge.
To make matters more difficult, whilst the index for a book is static, a Web search index needs to be constantly updated as websites change. Crawlers need to keep returning to pages previously crawled in order to update the index.
When someone enters and submits a search query the search engine will find pages that include that search phrase or something similar. In order for this process to produce useful information, the search engine must also undertake sorting of these results; this process is known as ranking.
Ranking
A search engine uses a wide variety of ranking factors when deciding which results to display. Each result will typically show a title, a short content highlight (“snippet”), sometimes an image, and a hyperlink to the page.
An important distinction should be made here between non-tracking search engines/services and those which undertake large levels of data collection. Mojeek and Gigablast are the only real search engines which do not engage in tracking. DuckDuckGo (and others) also offer some privacy and limited tracking, but all of them send your search queries to, and get results from, Microsoft (or Google and sometimes Yandex). Importantly when search engines engage in tracking, ranking will depend upon a large number of different “personalisation” factors and algorithms.
Pages found from the index, that match with a search query, will appear on the search page in order of relevance. Relevance is determined by the search engine’s ranking factors and algorithms; an explanation of which would require a much longer article. SEO (Search Engine Optimization) is about influencing the way in which search engines rank webpages. SEO is, of course, almost entirely focussed on Google ranking, since it dominates the search market.
With Mojeek since tracking is not used, the ranking of results will be obtained using objective factors. Google and Bing rank results based on data that it has collected or inferred about you. These inferences can come from cookies, aggregated data and machine learning (AI) algorithms. Tracking, data collection, and ranking practices by Big Tech has led to the prevalence of what is now recognised as surveillance capitalism.
How did we get here?
Few realise that many of the emerging and so-called search engines are actually search services. Sadly real search engines have become rarer as the Web has grown bigger and older. Still, it takes significant resources, innovation and resourcefulness to build and sustain a search engine business. At Mojeek we have existed as a business since 2009, slowly grown and now are focussed on developing our business model. We are deeply committed to our no tracking principles.
Would we tolerate a society where only two TV News Channels existed, say CNN and Fox News? Obviously not. And yet, we have effectively just two English-language search indexes; Bing and Google, owned by two US behemoths.