Is the Golden Age of Fair Use Over?

Isn’t Scraping the same as Crawling?
Web scraping, also known as data or content scraping, refers to the unauthorized use of bots to download website content, often for malicious purposes. Web scrapers often ignore robots.txt restrictions and may drain server resources. Web crawlers, by contrast, follow the robots.txt file and limit their requests to avoid overwhelming web servers.
Sometimes web scrapers will pretend to be a known web crawler. One strategy is to pretend to be GoogleBot in the hope of obtaining the widest access. So how do you identify these pretenders and scrapers?
It’s not a silver bullet but Cloudflare maintains a helpful and well informed list of “verified” good bots, manually approving well-behaved services that “benefit the broader Internet and honour robots.txt”. A respectful crawler will publish details of how it can be verified. Mojeek provides details on how to verify MojeekBot that can be used server side, as do other search engines.
Not All is Fair in Love and AI
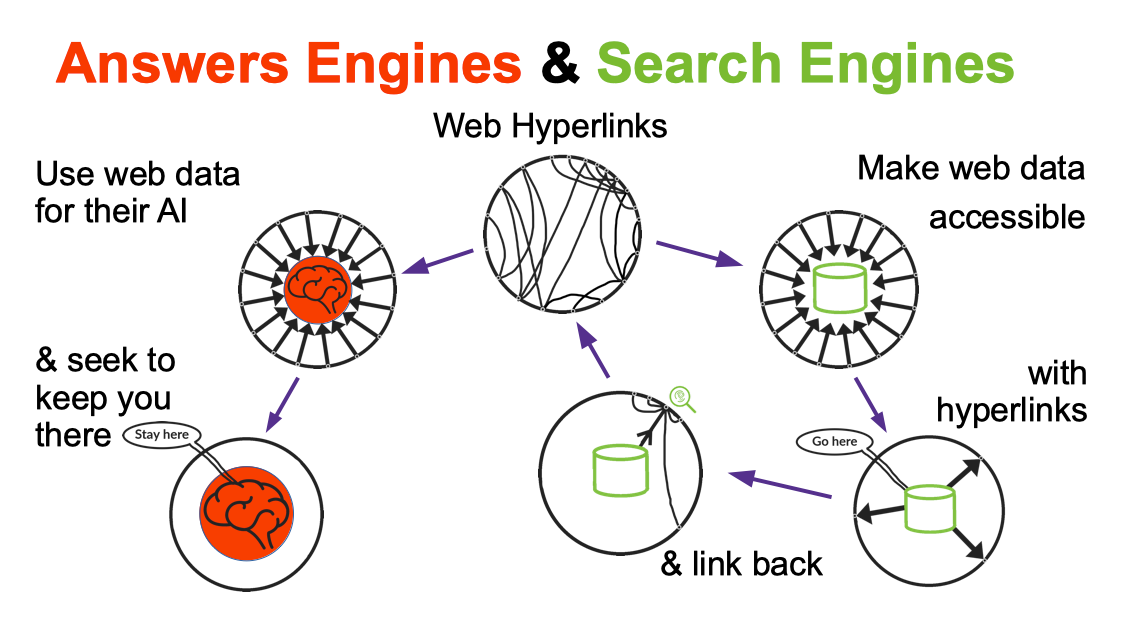
If you take from the web, you should give back. Search engines like Google and Bing used to do that with hyperlinks; sending traffic back to the web-pages which they have crawled and indexed. The voluntary arrangement of respecting robots.txt files and page meta tags, and linking back, is underpinned by the legal concept of fair usage.
The training of LLMs and the deployment of generative AI has seen companies riding roughshod over creators and publishers, abandoning fair usage. As we have explained before this started at Google back in 2005, with the addition of several features on its search page and notably Featured Snippets in 2015. Now they are putting AI search results above those organic links; in doing so, they are using LLM models that were probably trained on the search index they have built through crawling.
Google and OpenAI were not alone in this practice of using large-scale crawled datasets for training LLM models. Like others they started using data from the Common Crawl, which “maintains a free, open repository of web crawl data that can be used by anyone.” This resource advertised as a non-profit with “data accessible to researchers” has fuelled what has now become, some would say, a reckless commercial race to AI supremacy.
Where two years ago most AI model developers revealed their data sources, such as Common Crawl, nowadays commercial companies like OpenAI, Google, Microsoft, Anthropic and Meta no longer reveal in their research papers, or technical reports, the data sources they are using to train their AI models. Can you guess why?
Closing The Door as the Horse is Bolting
Still as websites, publishers and creators have become more aware of the usage of web data in AI models, they have started to take action. Content licensing deals are being struck, legal disputes are being thrown around and some sites are updating their robots.txt files. Below we will share data on the latest usage of robots.txt, to flag to crawlers the updated wishes of top websites.
The voluntary arrangement of robots.txt obviously depends on good actors and there seems to be fewer and fewer around. The whole situation is made worse because currently there is no robust way to declare that you want your content searchable on search engines, but not used for machine learning.
Companies can use their search engine crawler to obtain data for both purposes. This is why we proposed the simple NoML protocol.
To their credit, Google in September 2023 partially addressed this issue by defining a new crawler bot to be used for AI called Google-Extended, distinguishing it from GoogleBot (and other related) search crawlers. If you want to allow Google to index you for search you can allow GoogleBot (although this is optional and depends upon other rules, as allow is the default) and disallow Google-Extended for AI like this:

As Google puts it: “to control access to content on a site, a website administrator can choose whether to help these AI models become more accurate and capable over time”. Make of that what you will.
As far as we are aware, no other company has made such a move. If you want to appear in Bing search (allowing BingBot) there is no way to declare via robots.txt that Microsoft should not train, or use, your data for AI, and notably Copilot. Is Bing crawled data shared with OpenAI to train GPT and others? Who knows?
OpenAI claim that “training AI models using publicly available internet materials is fair use” and because of the robots.txt opt-out they finally announced in August 2023 they are being “good citizens”; announcing their crawler bot as GPTBot. Since GPT-3 was largely based on Common Crawl, what did data they scrape before August 2023, to train GPT-4 for example?
You may note that CCBot, the crawler from Common Crawl has long been declared, though interestingly it is not verified by Cloudflare. Their datasets having been used for LLMs for several years by OpenAI, Google and almost everyone in some shape or form.
Companies were ahead of the game and training models with data collected before they declared these new crawler bots. Have a look what happened when the GPTBot and Google-Extended crawlers were announced in the graph below from Originality.
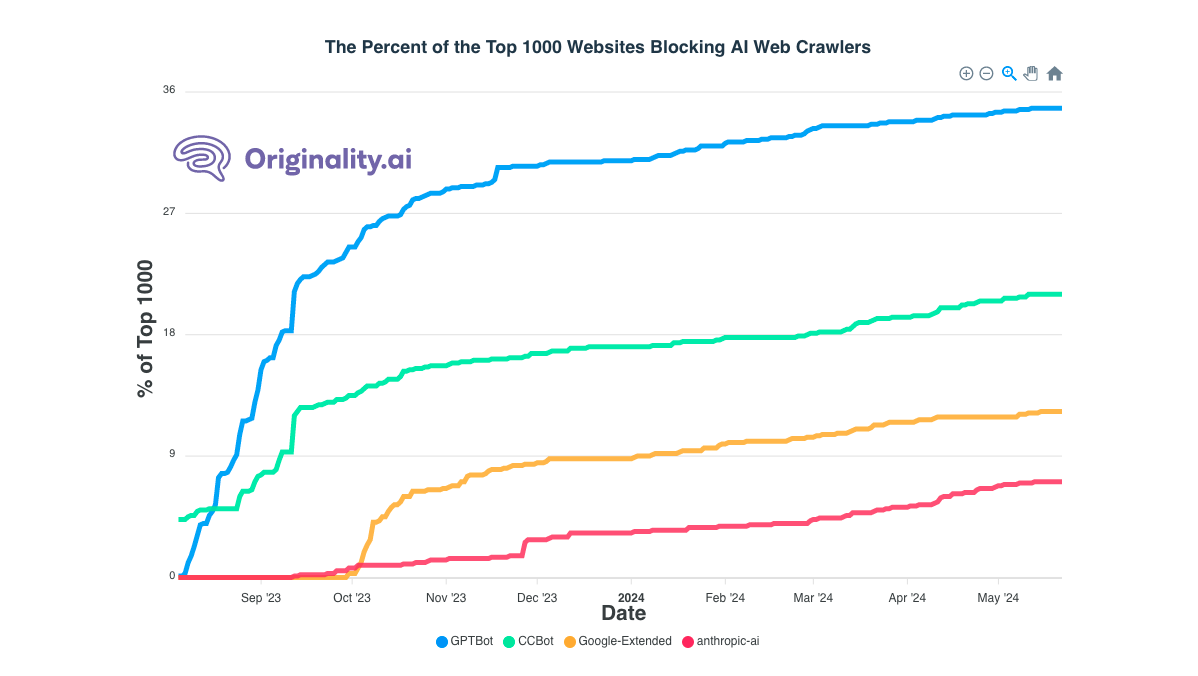
As you see some sites immediately began to disallow these AI crawlers.
Today there are a few sites requesting that all the four bots above keep out. Indeed.com, for example, are trying like this:

Though Anthropic may be getting a free pass here as their crawler is, at least now, called ClaudeBot. Apart from being unverified at Cloudflare this bot is widely reported as ignoring robots.txt anyway; one example here.
Industry Responses
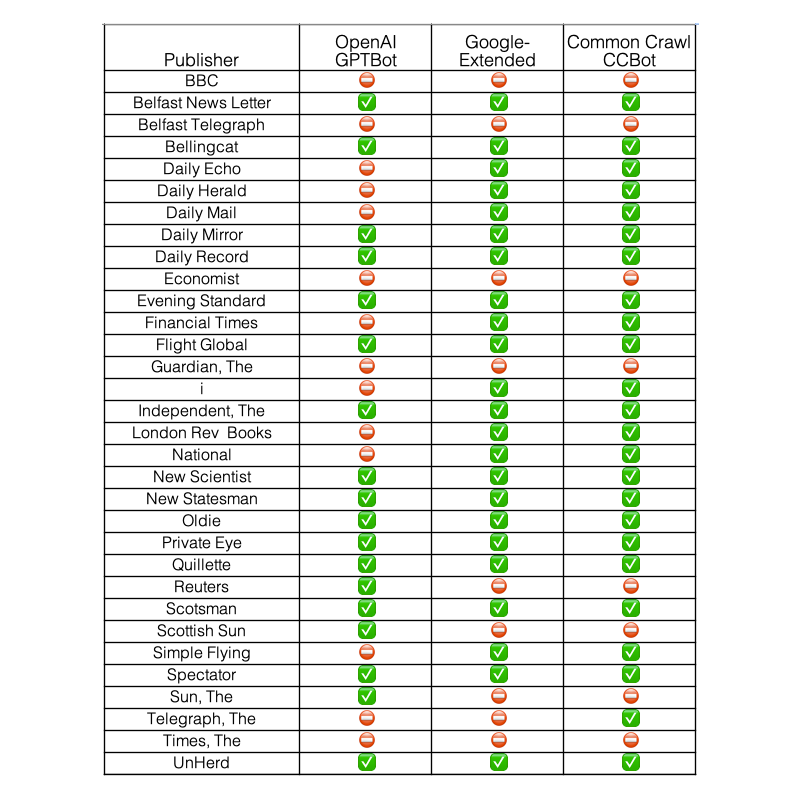
Newspaper publishers have been writing about these issues frequently since the release of ChatGPT, and have been gradually indicating their positions in robots.txt. These changes are being monitored live by Ben Welsh of Palewire across 1,231 global news sites. For a sample granular view here is the current status (May 20, 2024) for UK news publishers - ✅ indicates that a bot can crawl, ⛔ indicates that it is explicitly blocked.
And we can see, from further data monitored by Originality for the top 1,000 sites, that News and Media are currently the most proactive in disallowing AI crawlers. This is clearly shown in the chart below where we have analysed the current robots.txt disallows as reported by Originality.
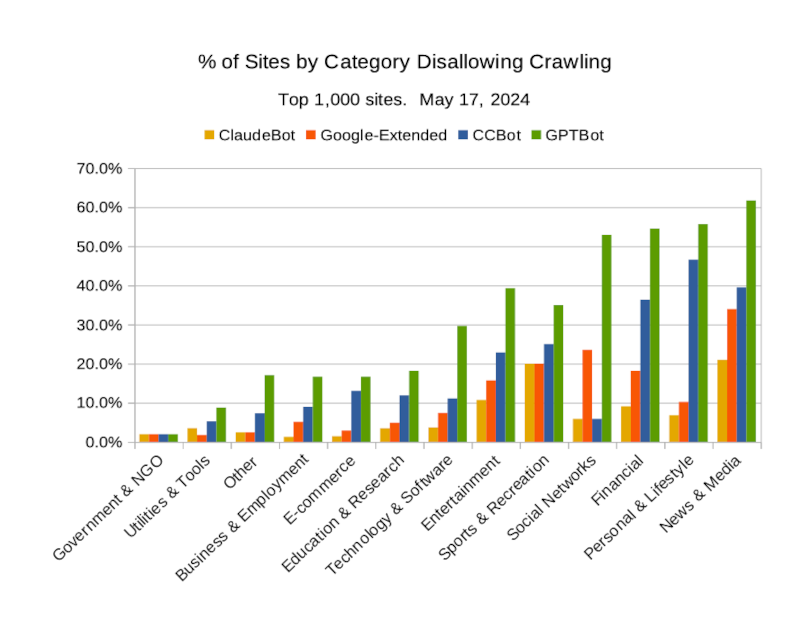
As we can see the least proactive are governments and NGOs; in fact sites all except ed.gov. Is this sector in parts blissfully unaware, and/or naively happy for the AI powers to extract and commercialise their content?
It’s no surprise that OpenAI’s GPTBot is disallowed more than the other three across all industry categories. Next most disallowed is Common Crawl’s CCBot, except with social networks. This seems counterintuitive, as you would have thought those sites would be technically savvy, and would also be tackling ClaudeBot better.
The rate of disallows might seem high from eyeballing the chart, but don’t be fooled; the overall average rate of disallowing is 6.1%. And remember this is for the top 1,000 sites. It’s a safe bet that the rates are lower for the next 9,000 sites and so on down the long-long tail. Sadly the small and independent sites won’t have the resources or muscle to get a licensing deal like the The Guardian or Reddit. AI is not only sucking from the web, it’s also likely to make the rich richer.
Looking Forward
Does training and deploying AI models on copyrighted works constitute fair use? Ultimately the courts may decide. The cases that will matter most, even for the rest of the world, will be in the US. These may be tested in court at some point, notably in the case of New York Times vs. Microsoft (and OpenAI). Though in that case don’t be surprised if an out-of-court settlement is made. Rather it seems deals may rule the era. Existing deals are known between OpenAI and Axel Springer, FT, and News Corp plus Reddit with both OpenAI and Google. There must be many more signed in private and/or underway with 35 known as reported here.
Meanwhile creators and smaller sites will get little. Hugely-reduced traffic from Google and little or nothing from the AI companies. By the time the law catches up, even if it falls on the side of creators, it will be too late for most.
Is there hope from new standards? The W3C have produced a report “AI & the Web: Understanding and managing the impact of Machine Learning models on the Web” and are considering the role that Web standardization may play in managing that impact. They are currently inviting comments on it, before 30th June 2024. Standards work may however move slower than tests of the law, and so that too will come too late for many.
Meanwhile at Mojeek we will continue to provide a search engine with links back to the sites that we have crawled. As detailed in this blog post in May 2023 our mission has always been about being a Search Engine not an Answer Engine.